
Since we first started building Bookhype, one of the challenges we faced was figuring out a way to accept book data form publishers, but also have the ability for site librarians to change that book data, without the publisher being able to change it back. Although you’d think the publishers would always send the most accurate, up-to-date information about the books they publish, sadly that’s […]
Category: Technical
Why building a Goodreads alternative is not so easy…
This post may get a little technical in some places, but you might learn something about the world of book data! If you’ve ever been involved in a discussion about how subjectively bad some people think Goodreads is, whatever the reasons are, maybe because it’s slow, has bad recommendations, doesn’t get active development, or just simply because it’s Amazon owned – you may have seen […]
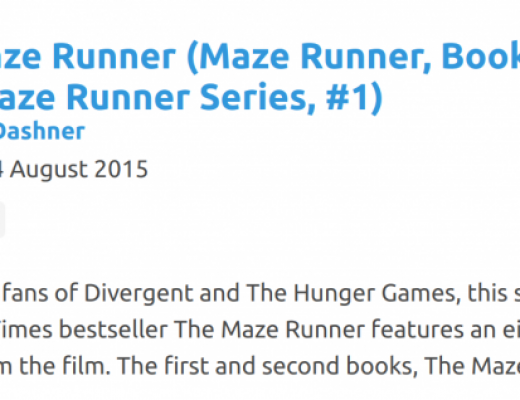
Book data parsing woes
Building Bookhype has given me an interesting look into the world of book metadata for the first time. My goals for Bookhype seemed pretty simple: Books by the same author should be correctly linked to the same author record, so that when you view that author’s profile you see all their books. Books in the same series should be linked to the same series record. […]
Delays and images
I’m feeling pretty frustrated that we haven’t been able to launch our beta yet. We’re still waiting on a few pieces before we can go live (even “beta live”) and I’m not sure when they’ll come through. Hopefully later this week! But in good news, we have book covers! We spent the weekend working on our automatic processes – collecting, sorting, and processing book data […]
We have a server!
A few days ago our server got provisioned and we’ve been tinkering with it ever since. We had a few teething problems, which took a few tiring hours of our time, but things are fundamentally working now! We’ve now mostly been testing deployments and running book imports. We’re working really hard on making the import process as fast as possible, because we’ll have a lot […]
Extracting series names from book titles – wins and failures
We’re still working hard on perfecting our code for removing series names from book titles. This definitely requires a lot of trial and error! Essentially our goal is to have three separate data pieces: Title of this book only. Name of the series it’s part of. This book’s position within that series. The tricky part is that the series name and/or position are often inserted […]
Two imports down, how many to go?
As I posted yesterday, we did our first significant test import with 130,000 records. We spent pretty much all of last night analyzing the results of that import and coming up with little tricks to improve some of the inconsistencies in the data. The main things we looked out for were: Different books by the same author linked under the same author record. Different editions […]
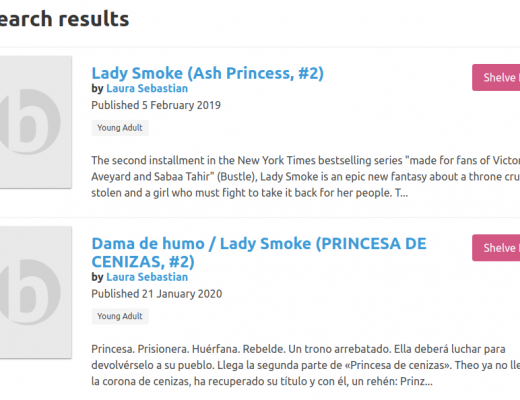
Frustrations from our first book data import
Last night we did our first significant test import of book data. Until now we’ve been testing smaller data sets between 5,000 and 25,000 book records. Last night we imported about 130,000 records. I spent this morning analyzing how the data came through and have a few things weighing on my mind. Editions in different languages In terms of end result, I want different translations […]